本月发表的《Scalable MatMul-free Language Modeling》新论文,研究人员提出 MatMul-free语言模型(MatMul-Free LM),该模型性能与最先进的Transformer相当,同时推理过程需要的存储器用量更少。
矩阵乘法(Matrix Multiplication,MatMul)是大多数神经网络运算的基本操作,归因于GPU针对MatMul操作进行一系列效能改进。
尽管MatMul在深度学习发挥关键作用,但它也是决定运算成本的一大关键,通常训练和推理阶段消耗大量执行时间和存储器存取,带来昂贵的运算成本。
来自加州大学圣克鲁兹分校、苏州大学、加州大学戴维斯分校及LuxiTech组成的研究团队,通过论文介绍可扩展的MatMul-Free LM。
研究表明即使达到十亿等级参数规模,也能完全消除大语言模型的MatMul操作,同时模型保有稳健性能。
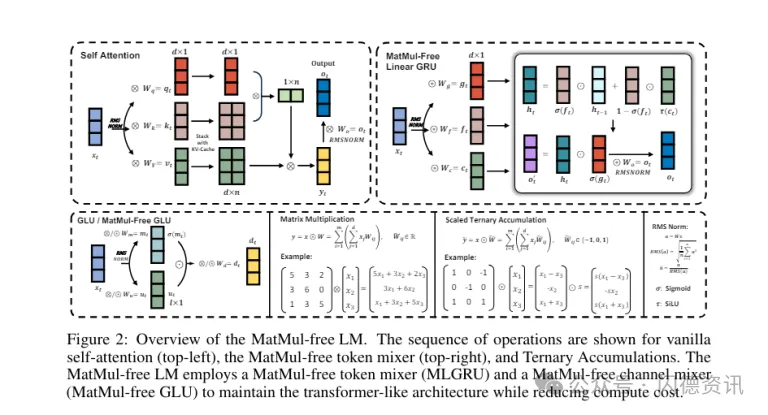
MatMul-free LM通过密集层和元素级阿达玛乘积采用加法运算来达成类似自注意力机制的功能。具体来说,三元权重用于消除密集层中的MatMul,类似二元神经网络(binary neural network,BNN)。
为了消除MatMul的自注意力机制,研究人员使闸门循环单元(Gated Recurrent Unit,GRU)最佳化,完全依赖元素乘积。
这种创新模型可与最先进的Transformer竞争,同时消除所有MatMul操作。
研究团队的架构视角受到Metaformer启发,Metaformer将Transformer概念化为由 token mixer和channel mixer组成。
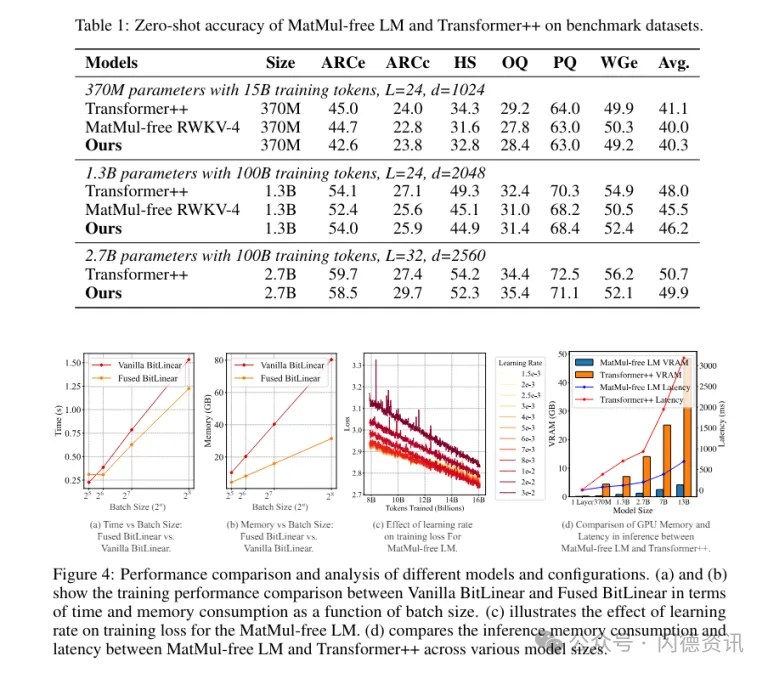
为了量化其轻量级模型的硬件优势,研究人员提供优化的GPU实作以及FPGA加速器,这种方法可将存储器使用量减少多达61%。
通过推理过程利用最佳化的内核,当与未优化的模型相比,MatMul-free LM的存储器用量减少10倍以上。
为了彻底评估他们提出架构的效率,研究团队在FPGA开发了一种定制化硬件解决方案,利用GPU功能以外的轻量级操作,成功在功耗13W情况下处理10亿参数规模的模型,以超出人类可读的吞吐量,使LLM接近大脑般的效率。
点击此处关注,获取最新资讯!




















18126200184





























我的评论
最新评论