端侧AI驱动:存储器
从“标准部件”向“系统级能力”演进
在端侧AI时代,存储器的产业定位正经历根本性重塑。正如消费级GPU与AI专用GPU在体系架构上的分流——前者依托通用芯片生态,后者面向完整AI系统产品进行深度定制。AI专用芯片凭借针对性的架构设计与系统级优化,能够更精准地响应终端AI设备对性能与能效的严苛要求,充分释放端侧AI的应用潜力。

这一趋势下,标准化存储已难以满足新一代AI终端对性能、功耗与系统协同的多元需求。行业普遍认为,端侧AI存储的核心诉求正聚焦于三大方向:高带宽与大容量、系统级封装(SiP)集成能力,以及面向应用场景的定制化服务。
这些要求与传统标准化存储生态形成本质差异,推动存储器的角色从单纯的数据载体,逐步演进为深度参与计算体系的关键节点,直接关乎AI应用的系统性能与终端用户体验,成为端侧AI基础设施中的核心组件之一。
基于上述判断,江波龙将战略重心锚定端侧AI集成存储,围绕具体应用场景开展产品定义与能力匹配,构建覆盖AI手机、辅助驾驶、智能穿戴、AI PC及具身机器人等领域的完整解决方案体系,为端侧AI存储创新确立清晰的场景导向,并与云端存储形成互补协同格局。

面对端侧AI存储带来的多样化、定制化挑战,江波龙主动破局,率先推动“端侧AI存储全链路定制服务Foundry模式”落地。该模式贯通芯片设计、硬件开发、固件与软件系统、封装工艺、工业设计、自动化测试、材料工程及生产制造等全产业链关键环节,通过跨环节协同与系统性技术整合,实现存储产品从设计到交付的全流程定制化与效率优化。
这一模式不仅突破了传统存储以单点性能升级为主导的发展路径,也为端侧AI时代提供了一种更具系统性与工程化特征的发展模式参考,更是江波龙布局端侧AI存储的核心策略。
SPU+iSA打造
端侧AI存算协同新范式
在端侧AI加速落地的背景下,存储系统正面临容量、带宽与成本难以兼顾的核心矛盾。大模型持续膨胀带来的KV Cache压力、I/O延迟问题以及DRAM成本约束,使传统“CPU+DRAM+SSD”架构逐渐触及瓶颈。由此,以“存算协同”为核心的新一代存储架构开始浮现。

在本次峰会上,江波龙首次系统性推出SPU(存储处理单元)与iSA(存储智能体)组合,构建起“芯片硬件+智能调度”的端侧AI存储技术闭环。不同于传统SSD主控,SPU基于5nm先进制程工艺打造,定位为面向智能存储架构的专用处理单元。其单盘最高容量达128TB,并通过存内无损压缩与HLC(高级缓存)技术在容量与成本之间实现有效平衡。其中,约2:1的压缩能力显著提升存储利用率,而冷热数据分层技术将部分数据下沉至SSD,使DRAM容量需求降低近40%。
在此基础上,iSA作为智能调度中枢,进一步解决端侧AI推理中的实际运行瓶颈。针对MoE大模型参数规模大、KV Cache快速膨胀以及I/O访问延迟等问题,iSA通过专家卸载、缓存管理与智能预取等机制,实现更高效的数据调度与资源分配。
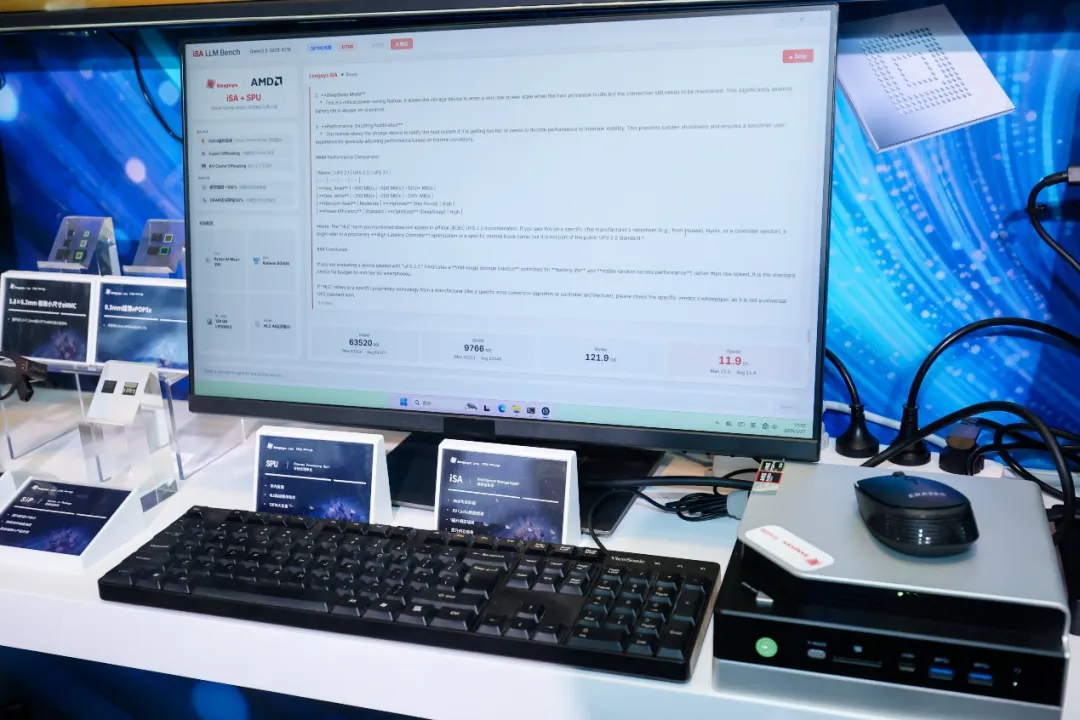
在与AMD平台的联合调优中,该架构已支持超大模型在端侧本地部署,并在长上下文场景下将DRAM占用降低近40%,为大模型端侧化提供了可行路径。
从技术本质来看,SPU与iSA所代表的路径,是将部分计算能力前移至存储侧,通过压缩、缓存与调度机制实现“存算协同”。这一架构带来的直接变化在于:显著降低大模型对DRAM的依赖,提升整体存储容量利用效率,并推动超大模型从云端走向端侧部署。内存由此从“被动数据载体”转向“主动参与计算”的关键节点,传统架构正在被重构。
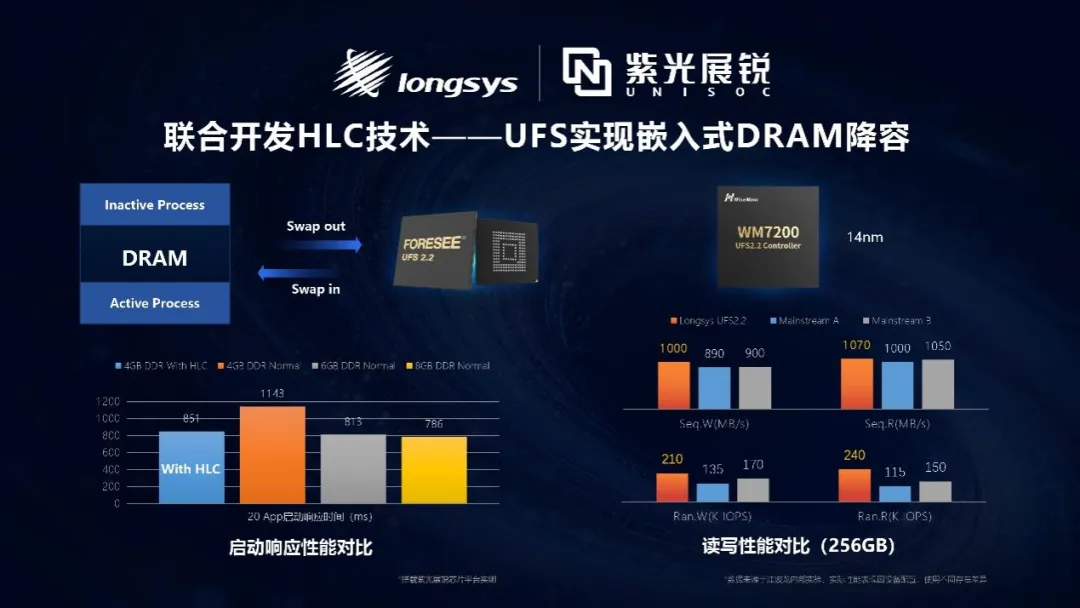
围绕“性能与成本平衡”这一端侧AI落地的核心命题,江波龙进一步将HLC技术与SPU、UFS等产品体系深度融合,实现AI PC与嵌入式端的全面落地。在PC侧,通过分层缓存设计构建AI专用高速缓存区,将大模型关键数据卸载至存储侧,在保障性能的同时降低DRAM配置需求;在嵌入式侧,江波龙与紫光展锐联合开发,即使在较低DRAM容量配置下,系统响应性能依然接近高配水平,有效优化终端BOM成本。
整体来看,这一系列技术路径正推动端侧AI存储实现2大关键突破——在降低DRAM需求以控制成本的同时,提升存储性能与带宽,为端侧AI的规模化落地提供了关键支撑。
全场景存储产品矩阵集体亮相
在本次MemoryS 2026展会上,江波龙系统性展示了面向端侧AI的全系列存储产品布局,覆盖从高性能计算到轻量化终端的多层级应用场景,体现出其从“单一器件”向“系统级解决方案”的全面升级。

在高性能存储领域,江波龙重点推出新一代PCIe Gen5 mSSD。该产品延续DRAM-less架构与20×30mm超小尺寸设计,兼容M.2 2230规格,并可灵活扩展至2242/2280及AI/固态存储卡、PSSD等多形态,在无需更改终端设计的前提下实现快速导入。
性能方面,产品顺序读写速度最高可达11GB/s与10GB/s,随机读写性能最高达2200K/1800K IOPS,单盘容量支持至8TB,能够充分满足AI PC等端侧设备对高带宽与大容量的需求。
同时,针对小尺寸高性能带来的散热挑战,江波龙创新引入VC相变液冷散热方案,通过多层复合散热结构,将高性能持续输出能力显著提升,在AI PC KV Cache高负载场景下具备更强稳定性与适配能力。

在轻量化与高度集成的端侧场景中,AI穿戴设备成为本次展示的另一大重点。江波龙围绕“小尺寸、低功耗、高性能”的核心需求,推出包括全球最小尺寸5.8×6.3mm eMMC及厚度仅0.5mm的ePOP5x等产品,全面体现其在系统级封装、自研主控及制造能力上的综合优势。
从产品矩阵来看,江波龙已构建覆盖ePOP、eMMC与UFS三大主流接口的完整穿戴存储体系:其中,ePOP系列通过集成闪存与内存,适用于AI眼镜与高端智能手表等对空间与集成度要求极高的设备;eMMC系列兼顾成本与性能,覆盖智能手表、运动相机与音频设备等主流应用;UFS系列则面向AR/VR及高性能影像设备,提供更高带宽以支持实时渲染与高码率数据处理。
目前,江波龙穿戴存储产品已广泛进入智能手表、TWS耳机、智能眼镜及运动相机等多个终端品类,覆盖全球主流品牌供应链。通过从高性能SSD到高度集成穿戴存储的完整产品布局,江波龙正构建起面向端侧AI时代的全场景存储解决方案能力。
从器件到系统
端侧AI重塑存储产业格局
端侧AI的加速落地,正在推动存储产业经历一场从底层架构到产品形态的深刻变革。在这场变革中,存储器的角色已不再局限于数据的承载者,而是逐步演变为深度参与计算体系的关键节点,成为决定端侧AI终端性能与用户体验的核心基础设施之一。
从SPU与iSA构建的存算协同新架构,到存储Foundry模式打通的全链路定制能力,再到覆盖AI PC、穿戴设备等全场景的产品矩阵,江波龙以系统化的技术布局与工程能力,清晰勾勒出端侧AI存储的演进路径。其背后体现的,不仅是一家存储厂商对产业趋势的精准判断,更是从“标准部件供应商”向“系统级能力构建者”的战略跃迁。
面向未来,随着AI应用从云端加速向终端渗透,存储与计算的边界将愈发模糊,性能、成本、功耗与体积之间的平衡将成为决定端侧AI规模化落地的关键。在这一进程中,能够率先构建“系统级能力”的存储厂商,将有望在产业价值链中占据更核心的位置。
正如行业所共识:端侧AI的竞争,终将回归到底层基础设施的竞争。而存储,正在成为这场竞争中最关键的变量之一。


















18126200184






























我的评论
最新评论